Architecture Overview
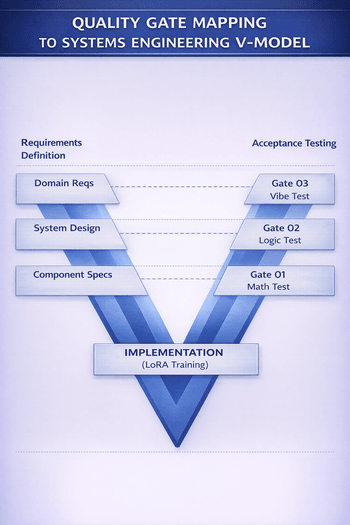
The system architecture follows a staged distillation pipeline pattern, where each component is decoupled and independently verifiable — a key systems engineering principle enabling incremental validation. The architecture comprises four primary subsystems:
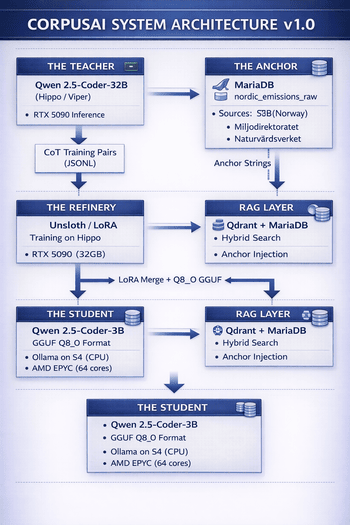
The 32-billion parameter teacher model runs on the Hippo/Viper GPU cluster (RTX 5090). It processes Anchor Data and generates Chain-of-Thought (CoT) reasoning pairs that form the training corpus for the student model. The teacher's role is to demonstrate how to think about emissions data — not just what the answer is.
The 3-billion parameter student model is the deployment target. Trained via LoRA fine-tuning on the teacher's distilled outputs and anchored to verified statistics, it achieves near-teacher-level accuracy at 10× the inference speed. Quantised to Q8_0 GGUF for CPU-only deployment on the S4 server (AMD EPYC).
The anchor layer is the system's "Ground Truth" guarantee. Raw emissions data from SSB (Statistisk sentralbyrå), Miljødirektoratet, and Naturvårdsverket is stored in a normalised MariaDB table and transformed into Natural Language Fact Sheets during training. This ensures zero hallucination on factual queries.
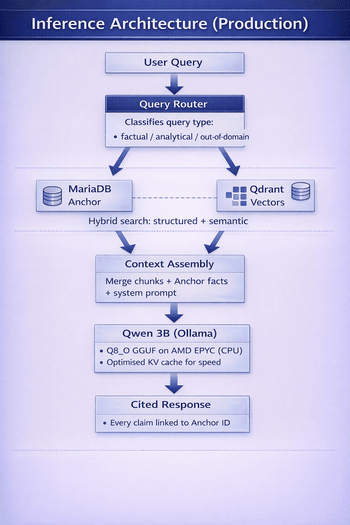
At inference time, a Retrieval-Augmented Generation (RAG) layer performs hybrid search across Qdrant vector embeddings and MariaDB structured data. Retrieved chunks and Anchor Data facts are injected into the prompt context, enabling the 3B student to provide cited, verifiable responses.